
IEnumerable i yield return w C#
Myślisz, że List<T> to domyślny wybór do przechowywania i zwracania danych w C#? Jeśli Twoja aplikacja operuje na małych zbiorach, pewnie masz rację. Ale co jeśli musisz przetworzyć plik CSV o rozmiarze 5 GB albo pobrać z bazy danych milion rekordów? Jeden naiwny błąd wystarczy, żeby serwer produkcyjny dostał OutOfMemoryException i padł w środku nocy.
W tym artykule zobaczysz, jak IEnumerable<T> i słowo kluczowe yield return pozwalają przetworzyć gigabajty danych, trzymając w pamięci RAM zaledwie jeden rekord na raz. Zrozumiesz, jak kompilator C# buduje pod spodem maszynę stanów, poznasz pułapkę Multiple Enumeration i dowiesz się, kiedy leniwe przetwarzanie może zrujnować Twoją wydajność I/O. Gotowy? Zaczynamy.
Dlaczego List<T> może zabić Twój serwer
Antywzorzec – ładowanie wszystkiego do pamięci

Klasyczny błąd, który regularnie pojawia się na code review w projektach komercyjnych:
// ANTYWZORZEC – katastrofa pamięciowa dla dużych zbiorów danych
// File.ReadAllLines() ładuje WSZYSTKIE linie z dysku do tablicy stringów naraz
public List<Transaction> GetAllTransactionsNaive(string filePath)
{
var transactions = new List<Transaction>();
foreach (var line in File.ReadAllLines(filePath)) // cały plik w RAM
{
transactions.Add(TransactionParser.Parse(line));
}
return transactions; // serwer właśnie dostał BOM
}Co tu się dzieje za kulisami?
Metoda File.ReadAllLines() wczytuje cały plik do pamięci jako tablicę stringów. Następnie każdy string jest parsowany do obiektu Transaction i dodawany do List<Transaction>. Dla pliku 5 GB RAM-u zajętego będzie więcej niż 5 GB, bo do każdego stringa dochodzi jeszcze narzut obiektu .NET.
Large Object Heap – cichy zabójca wydajności
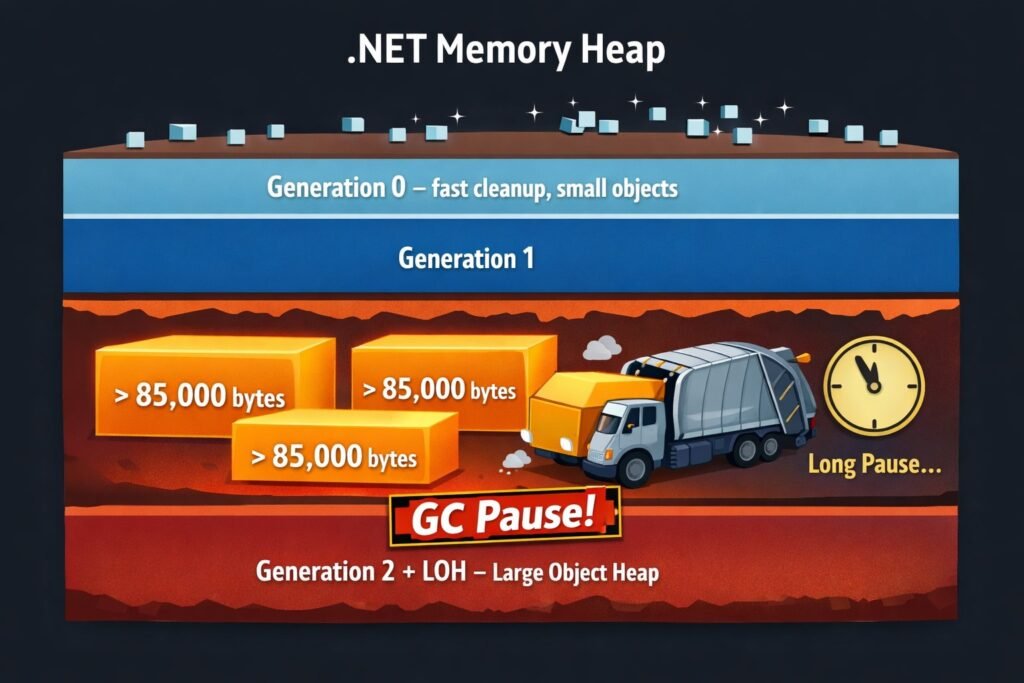
W .NET obowiązuje twarda reguła: obiekty o rozmiarze ≥ 85 000 bajtów trafiają nie na normalną stertę, lecz na Large Object Heap (LOH). To ma dwie poważne konsekwencje:
- LOH nie jest kompaktowany podczas standardowych GC – fragmentacja pamięci rośnie z każdą alokacją.
- Full GC (Gen 2) wymagany do zebrania LOH potrafi zawiesić aplikację na sekundy (tzw. GC pauses).
Wystarczy kilka żądań do serwisu, które każde ładuje duży zbiór danych, i aplikacja zaczyna odpowiadać z opóźnieniami – zanim w ogóle rzuci OutOfMemoryException.
Złożoność pamięciowa tego podejścia: O(N) – im więcej danych, tym więcej RAM-u.
H2: IEnumerable i yield return – leniwe przetwarzanie strumieniowe
H3: Rozwiązanie – jeden rekord na raz
Zamiast pakować wszystko do listy, zmieniamy sygnaturę metody i używamy yield return:
// BEST PRACTICE – odroczone wykonanie (Deferred Execution), złożoność pamięciowa O(1)
// StreamReader czyta plik partiami (buforuje), a nie w całości
public IEnumerable<Transaction> GetTransactionsLazily(string filePath)
{
using var stream = new StreamReader(filePath);
string? line;
while ((line = stream.ReadLine()) != null)
{
// yield return "zamraża" metodę i zwraca jeden element do pętli wywołującej.
// Metoda wznawia działanie dopiero przy kolejnym MoveNext().
yield return TransactionParser.Parse(line);
}
// using gwarantuje zamknięcie pliku po zakończeniu lub przerwaniu iteracji
}Metafora:
To jak czytanie książki, nie musisz przeczytać całości naraz, żeby znać jej treść. Czytasz linijkę po linijce, a reszta książki spokojnie czeka.
Złożoność pamięciowa: O(1) – niezależnie od rozmiaru pliku, w RAM-ie masz zawsze jeden obiekt.

Jak kompilator C# buduje maszynę stanów
Możesz się zastanawiać: Zwracam Transaction, a sygnatura mówi IEnumerable<Transaction>. Jak to się kompiluje bez tworzenia kolekcji?
To właśnie jest magia yield return. Kiedy kompilator C# napotka to słowo kluczowe, nie tworzy żadnej kolekcji w pamięci. Zamiast tego generuje w tle prywatną klasę – maszynę stanów (State Machine), która implementuje interfejs IEnumerator<Transaction>.
Cykl życia maszyny stanów krok po kroku
Klient (foreach) Maszyna stanów (wygenerowana przez kompilator)
│ │
│──── GetEnumerator() ────────▶│
│ │
│──── MoveNext() ─────────────▶│ ← wchodzi do GetTransactionsLazily,
│ │ otwiera plik, czyta pierwszą linię,
│ │ parsuje → zapisuje stan
│◀─── Current = Transaction ── │ ← "zamraża" metodę przy yield return
│ │
│ [przetwarza obiekt] │
│ │
│──── MoveNext() ─────────────▶│ ← "odmraża" metodę DOKŁADNIE
│ │ po yield return, czyta kolejną linię
│◀─── Current = Transaction ───│
│ ... │
│──── MoveNext() ─────────────▶│ ← EOF, pętla while kończy się
│◀─── false ───────────────────│ ← iterator skończonyKluczowa obserwacja:
Jako programista piszesz prosty, sekwencyjny kod z pętlą while. Kompilator bierze na siebie całą złożoność zarządzania stanem. Nie musisz ręcznie implementować IEnumerator<T>, pilnować liczników ani zarządzać zasobami.
Co z otwartym plikiem – czy grozi wyciek zasobów?
Nie. Blok using współpracuje z yield return w pełni bezpiecznie. Gdy iteracja zakończy się naturalnie (koniec danych) lub zostanie przerwana (break w foreach), kompilator generuje kod, który wywoła Dispose() na StreamReader. Plik zostanie zamknięty w każdym scenariuszu.
H2: Klasy pomocnicze – separacja odpowiedzialności
Przed testem wydajnościowym warto zobaczyć strukturę kodu. W realnych projektach zawsze separujemy logikę odczytu danych od logiki transformacji:
// Rekord reprezentujący jeden wiersz CSV
public record Transaction(string Id, DateTime Date, decimal Amount, string Status);// Separacja logiki parsowania – łatwiejsze testowanie jednostkowe
namespace EnumerableDemo;
public static class TransactionParser
{
public static Transaction Parse(string csvLine)
{
var parts = csvLine.Split(',');
return new Transaction(
Id: parts[0],
Date: DateTime.Parse(parts[1]),
Amount: decimal.Parse(parts[2]),
Status: parts[3]
);
}
}// Helper do generowania danych na potrzeby dema
// (1 milion to ok. 80 MB czystego tekstu)
// (1o milion to ok. 800 MB czystego tekstu)
private static void GenerateDummyCsv(string path, int rows)
{
if (File.Exists(path)) return;
using var writer = new StreamWriter(path);
var random = new Random(42);
var statuses = new[] { "Success", "Failed", "Pending" };
for (int i = 0; i < rows; i++)
{
writer.WriteLine($"{Guid.NewGuid()},{DateTime.UtcNow.AddMinutes(-i):O},{random.Next(10, 10000) + random.NextDouble():F2},{statuses[random.Next(statuses.Length)]}");
}
}Dlaczego tak?
Klasa TransactionParser z jedną odpowiedzialnością (Single Responsibility Principle) jest łatwa do testowania i wymiany. Generator danych pozwala odtworzyć środowisko produkcyjne bez zewnętrznych plików.
Starcie dwóch podejść – pomiar pamięci w praktyce
Kod testowy w Program.cs
using System.Diagnostics;
public class Program
{
private const string FilePath = "transactions_large.csv";
public static void Main()
{
Console.WriteLine("Generowanie pliku testowego (ok. 1 mln wierszy)...");
GenerateDummyCsv(FilePath, 10_000_000);
var repo = new TransactionRepository();
#region SCENARIUSZ 1: Katastrofa pamięciowa (Antywzorzec)
Console.WriteLine("\n--- SCENARIUSZ 1: Naiwne ładowanie do Listy ---");
var memoryBeforeNaive = GC.GetTotalMemory(true);
var naiveList = repo.GetAllTransactionsNaive(FilePath);
var memoryAfterNaive = GC.GetTotalMemory(true);
Console.WriteLine($"Zużycie pamięci RAM: {(memoryAfterNaive - memoryBeforeNaive) / 1024 / 1024} MB");
#endregion
#region SCENARIUSZ 2: Leniwe przetwarzanie (Best Practice)
Console.WriteLine("\n--- SCENARIUSZ 2: IEnumerable z yield return ---");
var memoryBeforeLazy = GC.GetTotalMemory(true);
var lazyTransactions = repo.GetTransactionsLazily(FilePath); // UWAGA: Tu nic się jeszcze nie wykonuje!
decimal totalAmount = 0;
int failedCount = 0;
foreach (var tx in lazyTransactions)
{
totalAmount += tx.Amount;
if (tx.Status == "Failed")
failedCount++;
}
var memoryAfterLazy = GC.GetTotalMemory(true);
Console.WriteLine($"Suma transakcji: {totalAmount}, Błędnych: {failedCount}");
Console.WriteLine($"Zużycie pamięci RAM (Netto): {(memoryAfterLazy - memoryBeforeLazy) / 1024 / 1024} MB");
#endregion
#region SCENARIUSZ 3: Pułapka Multiple Enumeration
Console.WriteLine("\n--- SCENARIUSZ 3: Pułapka Multiple Enumeration ---");
var stopwatch = Stopwatch.StartNew();
// Pierwszy odczyt z dysku (cały plik)
var count = lazyTransactions.Count();
Console.WriteLine($"Czas Count(): {stopwatch.ElapsedMilliseconds} ms");
stopwatch.Restart();
// DRUGI odczyt z dysku (plik otwierany ponownie!)
var anyFailed = lazyTransactions.Any(t => t.Status == "Failed");
Console.WriteLine($"Czas Any(): {stopwatch.ElapsedMilliseconds} ms");
#endregion
}
#region Helper do generowania danych na potrzeby dema
// (1 milion to ok. 80 MB czystego tekstu)
// (1o milion to ok. 800 MB czystego tekstu)
private static void GenerateDummyCsv(string path, int rows)
{
if (File.Exists(path)) return;
using var writer = new StreamWriter(path);
var random = new Random(42);
var statuses = new[] { "Success", "Failed", "Pending" };
for (int i = 0; i < rows; i++)
{
writer.WriteLine($"{Guid.NewGuid()},{DateTime.UtcNow.AddMinutes(-i):O},{random.Next(10, 10000) + random.NextDouble():F2},{statuses[random.Next(statuses.Length)]}");
}
}
#endregion
}Wynik w profilerze Visual Studio:
- List<T>: gwałtowny skok pamięci, dane trafiają na LOH, GC zaczyna pracować w pocie czoła.
- IEnumerable + yield return: niemal płaska linia. Każdy Transaction żyje przez ułamek sekundy w Gen 0 – najtańsza możliwa kategoria dla GC.
Pułapka Multiple Enumeration – obosieczny miecz
Leniwe przetwarzanie ma jeden poważny efekt uboczny, o którym wielu juniorów (i nie tylko) zapomina. IEnumerable to obietnica, nie pudełko z danymi.
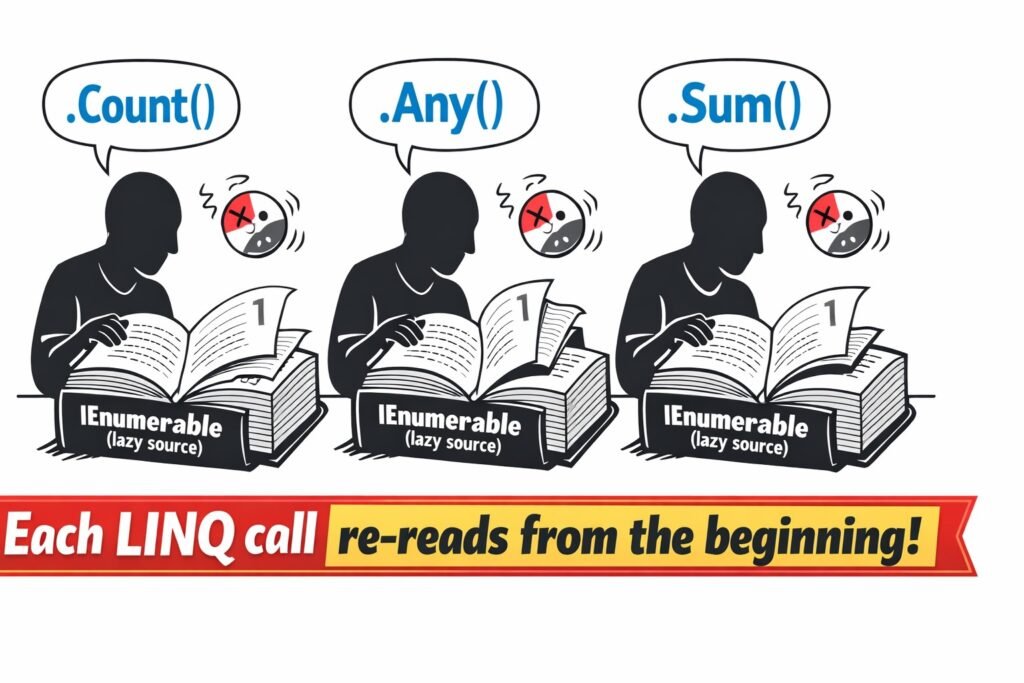
IEnumerable<Transaction> lazyTransactions = GetTransactionsLazily("transactions.csv");
// PUŁAPKA: każde wywołanie LINQ ponownie czyta plik od początku!
var count = lazyTransactions.Count(); // 1. pełny odczyt pliku z dysku
var hasAny = lazyTransactions.Any(); // 2. PONOWNY odczyt pliku od początku
var sum = lazyTransactions.Sum(t => t.Amount); // 3. TRZECI odczyt plikuAnalogia:
To jak gdybyś za każdym razem, gdy chcesz sprawdzić coś w książce, zaczynał czytać ją od pierwszej strony. Dla pliku 5 GB oznacza to 3 × 5 GB operacji I/O.
Jak unikać Multiple Enumeration
Opcja 1 – Jedna pętla foreach, wszystkie statystyki naraz:
// Jedno przejście przez plik, wszystkie obliczenia w jednej pętli
decimal sum = 0;
int count = 0;
foreach (var tx in GetTransactionsLazily(filePath))
{
sum += tx.Amount;
count++;
}
// Wynik: jeden odczyt pliku, pełne daneOpcja 2 – Materializacja przez .ToList() (tylko gdy dane są małe!):
// TYLKO gdy wiesz, że zbiór jest bezpieczny dla pamięci
var transactions = GetTransactionsLazily(filePath).ToList(); // materializacja
var count = transactions.Count; // O(1) – już w pamięci
var sum = transactions.Sum(t => t.Amount); // jedno przejście po liście⚠️ Ostrzeżenie:
.ToList() na strumieniu 5 GB danych sprawi, że wrócisz do punktu wyjścia – pełna lista w RAM-ie, LOH i GC pauses.
Checklista – kiedy używać IEnumerable z yield return, a kiedy List\<T\>
| Sytuacja | Rekomendacja |
| Przetwarzanie dużych plików CSV/JSON | ✅ IEnumerable + yield return |
| Streaming z bazy danych (duże zbiory) | ✅ IEnumerable + yield return |
| Potrzebujesz wielokrotnie iterować po danych | ⚠️ List<T> (jeśli dane małe) lub jedna pętla |
| Znany, mały zbiór danych (< kilka MB) | ✅ List<T> – prostsze i wystarczające |
| Przekazujesz dane do wielu konsumentów | ⚠️ Zmaterializuj do List<T> lub Array |
| API zwracające dane do klienta (pagination) | ✅ IEnumerable + yield return |
Porównanie złożoności pamięciowej – O(N) vs O(1)
Złożoność pamięciowa:
List<T>:
RAM ↑ │ ████████████████████████
│ ████████████████████████████████
│████████████████████████████████████████
└────────────────────────────────────────▶ N (liczba rekordów)
Więcej danych = więcej RAM
IEnumerable + yield return:
RAM ↑ │ ──────────────────────────────────────
│ (jedna jednostka, zawsze)
└────────────────────────────────────────▶ N (liczba rekordów)
Więcej danych ≠ więcej RAMList<T> O(N):
każdy nowy rekord = więcej RAM. Przy N = 1 000 000 rekordów możesz potrzebować setek megabajtów.
IEnumerable + yield return O(1):
niezależnie od N, w pamięci masz zawsze jeden rekord. Obiekty o krótkim czasie życia (jedna iteracja foreach) trafiają do Generacji 0 GC – najszybsza i najtańsza możliwa kolekcja pamięci.
Podsumowanie – IEnumerable to obietnica, nie pudełko
- ✅ IEnumerable<T> to nie kolekcja – to instrukcja „jak” pobierać dane w przyszłości. Samo przypisanie do zmiennej nie wykonuje żadnej pracy.
- ✅ yield return generuje maszynę stanów – kompilator C# tworzy prywatną klasę implementującą IEnumerator<T>, która pamięta stan między wywołaniami MoveNext().
- ✅ Złożoność pamięciowa spada z O(N) do O(1) – dla dużych zbiorów danych (pliki, bazy danych) to różnica między stabilnym serwisem a OutOfMemoryException o 3:00 w nocy.
- ✅ using + yield return = bezpieczeństwo zasobów – pliki i połączenia są zamykane poprawnie zarówno przy normalnym zakończeniu, jak i przy break w pętli.
- ⚠️ Pułapka Multiple Enumeration – każde wywołanie LINQ na leniwym IEnumerable może ponownie wykonać całą operację I/O. Rób obliczenia w jednej pętli lub świadomie materializuj przez .ToList().
Zobacz także — powiązane artykuły
👉 MCP w .NET (C#) – jak zbudować serwer AI krok po kroku
👉 Tworzenie klas i obiektów w C# — kompletny przewodnik
👉 Pattern Matching w C# – switch expressions i type patterns
Masz pytania o IEnumerable, yield return lub optymalizację pamięci w .NET?
Zostaw komentarz poniżej – chętnie odpowiem i rozwinę temat, który Cię interesuje.
📧 Chcesz więcej takich materiałów?
Zapisz się do Lista VIP i otrzymuj co tydzień praktyczne porady o .NET, C# i architekturze aplikacji – bez spamu, tylko wartościowy content.
⭐ Jeśli artykuł był pomocny – udostępnij go komuś, kto właśnie uczy się C# lub walczy z problemami pamięciowymi w .NET. Dzięki!
📺 Wolisz video? Cały tutorial z live codem i pomiarem RAM w profilerze Visual Studio znajdziesz na moim kanale YouTube.