
ASP.NET Core wprowadzenie do GraphQL
Wyobraź sobie, że budujesz aplikację webową, która potrzebuje danych z Twojej bazy danych. Tradycyjne API zwracają wszystkie dane, niezależnie od tego, czego szukasz. To marnowanie czasu i transferu danych. GraphQL to inne rozwiązanie – pozwala Ci pobrać tylko to, czego potrzebujesz. Jest to elastyczne i wydajne narzędzie, które ułatwia tworzenie aplikacji webowych.
GraphQL to język zapytań, który tworzy elastyczne i wydajne interfejsy API, zapewniając płynne i dynamiczne środowisko programistom i użytkownikom. GraphQL pozwala na dokładne przeszukiwanie danych bez obciążania sieci niepotrzebnymi danymi. Dodatkowo schemat GraphQL zapewnia przejrzysty opis sposobu odpytywania danych, co ułatwia tworzenie aplikacji i współpracę pomiędzy zespołami frontendowymi i backendowymi.
W tym artykule pokaże, jak dodać GraphQL do prostej aplikacji ASP.NET Core. Użyjemy do tego kilku pakietów NuGet, które pomogą nam zdefiniować dane i połączyć się z bazą danych.
Co to jest GraphQL?
Wyobraź sobie, że chcesz zamówić pizzę. W tradycyjnej pizzerni dostajesz pizzę z góry określonymi składnikami. To jak tradycyjne API – dostajesz dane, które serwer zdecyduje się Ci wysłać, nawet jeśli nie potrzebujesz wszystkich.
GraphQL działa inaczej. To jak zamawianie pizzy z własnymi składnikami. Mówisz dokładnie, czego chcesz – jaki rodzaj ciasta, jaki sos i jakie dodatki. Dostajesz tylko to, co zamówiłeś, bez zbędnych elementów.
To właśnie daje GraphQL – precyzję i kontrolę. Możesz żądać tylko tych danych, których potrzebujesz, co oszczędza czas i transfer danych. Jest to szczególnie ważne w przypadku aplikacji mobilnych, gdzie każdy bajt ma znaczenie.
Dodatkowo GraphQL jest bardzo elastyczny. Możesz łatwo łączyć dane z różnych źródeł, co ułatwia tworzenie złożonych aplikacji.
Jeśli jesteś początkującym programistą, pomyśl o GraphQL jak o spersonalizowanym menu w restauracji. Wybierasz tylko to, czego potrzebujesz, i dostajesz to w idealnej formie. To potężne narzędzie, które może znacząco ułatwić Twoją pracę.
Podsumowując:
- GraphQL to język zapytań API, który pozwala na precyzyjne żądanie danych.
- Dostajesz tylko to, czego potrzebujesz, co oszczędza czas i transfer danych.
- GraphQL jest elastyczny i łatwy w użyciu.
Kiedy warto używać GraphQL
GraphQL to świetne narzędzie do pobierania danych z API, ale nie zawsze jest najlepszym wyborem. Oto kilka sytuacji, w których warto rozważyć użycie GraphQL:
- Elastyczność zapytań:
W GraphQL możesz zażądać tylko tych danych, których potrzebujesz, bez zbędnych informacji, unikając w ten sposób przeciążenia danych, które często występuje w przypadku tradycyjnych interfejsów API RESTful. - Redukcja wielokrotnych wywołań API:
W wielu przypadkach pojedyncze wywołanie GraphQL może dostarczyć wszystkich danych potrzebnych dla danej wizualizacji lub funkcjonalności, eliminując w ten sposób potrzebę wielokrotnych wywołań API. - Masz skomplikowane dane:
Jeśli Twoje dane mają wiele powiązań między różnymi typami obiektów, GraphQL może ułatwić poruszanie się po tych relacjach i pobieranie potrzebnych informacji. - Chcesz przyszłościowo rozwijać API:
GraphQL pozwala na dodawanie nowych pól i typów danych bez psucia istniejących aplikacji. To ułatwia rozbudowę API w miarę rozwoju projektu. - Masz różne typy klientów:
Jeśli Twoje API ma obsługiwać różne rodzaje klientów, np. aplikacje mobilne i internetowe, GraphQL pozwala zapewnić każdemu klientowi dokładnie te dane, które potrzebuje, bez tworzenia odrębnych wersji API.
Pamiętaj jednak, że użycie GraphQL powoduje również dodatkową złożoność systemu, szczególnie w porównaniu z prostymi interfejsami API RESTful. Istnieją również sytuacje, w których może to nie być najwłaściwszy wybór:
- Proste API:
Jeśli Twoje API jest proste z jasno zdefiniowanymi punktami końcowymi i prostymi zapytaniami, RESTful może być prostszym i bardziej wydajnym rozwiązaniem, ponieważ GraphQL wprowadza warstwę złożoności, która w prostych przypadkach może nie być uzasadniona. - Niska złożoność danych:
Jeśli Twoje dane i relacje między obiektami są proste, RESTful może być łatwiejszy w użyciu i przewidywalny w działaniu, w którym można dokładnie przewidzieć, co zostanie zwrócone z każdego punktu końcowego. - Ograniczone zasoby:
Wdrożenie i utrzymanie API GraphQL wymaga pewnej wiedzy i doświadczenia. Jeśli Twój zespół nie jest z nim zaznajomiony lub masz ograniczone zasoby, RESTful może być prostszym wyborem. - Optymalizacja buforowania:
Buforowanie danych w GraphQL może być bardziej skomplikowane niż w RESTful, gdzie punkty końcowe zwracają bardziej przewidywalne i buforowane odpowiedzi.
Podsumowując:
GraphQL to potężne narzędzie, ale ważne jest, aby wybrać je mądrze. Dokładnie przeanalizuj potrzeby swojego projektu i upewnij się, że Twój zespół posiada odpowiednie umiejętności, aby z niego korzystać.
Pamiętaj, że zawsze możesz zacząć od RESTful, a później przejść do GraphQL, jeśli okaże się, że jest to dla Ciebie lepszy wybór.
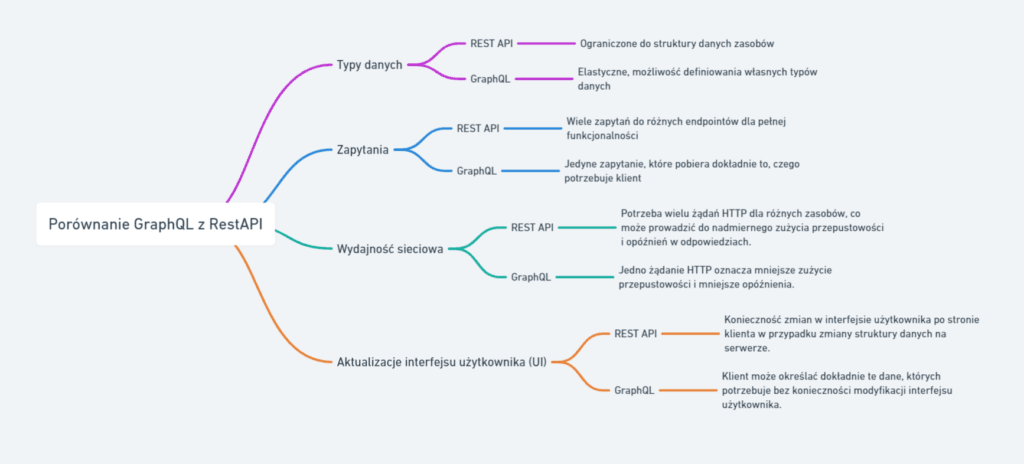
Poniżej znajduje się obraz porównujący główne różnice między zapytaniem GraphQL a żądaniem API REST podczas uzyskiwania dostępu do danych.
GraphQL w ASP.NET Core
GraphQL to technologia, którą można wdrożyć w różnych środowiskach, w tym w ASP.NET Core, który oferuje wiele funkcji do tworzenia interfejsów API. Aby dodać obsługę GraphQL do ASP.NET Core, należy skorzystać z odpowiednich bibliotek i narzędzi.
Istnieje kilka popularnych bibliotek, które umożliwiają integrację GraphQL z aplikacjami ASP.NET Core, np. GraphQL.NET i Hot Chocolate.
GraphQL.NET to biblioteka GraphQL dla .NET, która umożliwia łatwe dodanie serwera GraphQL do aplikacji ASP.NET Core. Zapewnia pełne wsparcie przy tworzeniu schematów GraphQL, obsłudze zapytań i wykonywaniu rozdzielczości danych.
Hot Chocolate To framework GraphQL dla .NET, który bezproblemowo integruje się z aplikacjami ASP.NET Core. Oferuje zaawansowane funkcje, takie jak obsługa podejścia schema-first and code-first, złożona obsługa zapytań, integracja Entity Framework Core i obsługa subskrypcji w czasie rzeczywistym.
Biblioteki te zapewniają narzędzia i abstrakcje, które ułatwiają wdrażanie serwerów GraphQL w aplikacjach ASP.NET Core, umożliwiając programistom skupienie się na logice biznesowej aplikacji.
Ćwiczenie GraphQL w ASP.NET Core: Stwórzmy bloga
W tym ćwiczeniu zbudujemy proste API bloga w ASP.NET Core, które będzie obsługiwać GraphQL. Będziemy mogli dodawać, pobierać i modyfikować wpisy blogowe oraz komentarze do nich.
Wyobraź sobie, że nasz blog staje się bardzo popularny i otrzymuje setki komentarzy. Musimy je analizować, aby tworzyć statystyki. GraphQL idealnie się do tego nadaje, ponieważ pozwala nam na precyzyjne filtrowanie i pobieranie danych, których potrzebujemy.
Wymagania
Do rozpoczęcia tego ćwiczenia będziesz potrzebować:
- Zainstalowana platforma .NET 8
- Visual Studio Code lub inne IDE
Dostęp do kodu źródłowego projektu można uzyskać tutaj
Aby utworzyć aplikację, możesz użyć następujących poleceń
dotnet new webapi -n MyBlog
cd MyBlog
i pobierz pakiety NuGet:
dotnet add package Microsoft.EntityFrameworkCore.Sqlite --version 8.0.1
dotnet add package Microsoft.EntityFrameworkCore.Tools --version 8.0.1
dotnet add package Microsoft.EntityFrameworkCore.Design --version 8.0.1
dotnet add package HotChocolate.AspNetCore --version 14.0.0-p.29
dotnet add package HotChocolate.Data.EntityFramework --version 14.0.0-p.29
dotnet add package Faker.Net --version 2.0.163
Tworzenie modeli
- Otwórz aplikację w swoim IDE.
- Utwórz nowy folder o nazwie „Models”.
- W folderze „Models” utwórz klasy, które reprezentują jednostki aplikacji.
Post
using System.ComponentModel.DataAnnotations;
namespace MyBlog.Models;
public class Post
{
[Key]
public Guid Id { get; set; }
public string Title { get; set; }
public string Content { get; set; }
public string Author { get; set; }
public DateTime CreatedAt { get; set; }
public ICollection<Comment> Comments { get; set; }
public Post()
{
Id = Guid.NewGuid();
CreatedAt = DateTime.UtcNow;
}
}Komentarz
using System.ComponentModel.DataAnnotations;
using System.ComponentModel.DataAnnotations.Schema;
namespace MyBlog.Models;
public class Comment
{
[Key]
public Guid Id { get; set; }
public string Content { get; set; }
public string Author { get; set; }
public DateTime CreatedAt { get; set; }
[ForeignKey("PostId")]
public Guid PostId { get; set; }
public Post Post { get; set; }
public Comment()
{
Id = Guid.NewGuid();
CreatedAt = DateTime.UtcNow;
}
}
Tworzenie kontekstu bazy danych
Kolejnym krokiem jest konfiguracja bazy danych. W tym poście będziemy używać SQLite, który jest relacyjną bazą danych i zwykle jest przechowywany w tym samym katalogu, co aplikacja. Dodatkowo będziemy wykorzystywać Entity Framework Core do obsługi automatycznego generowania bazy danych, tabel i manipulacji danymi.
Tworzenie kontekstu bazy danych kroki:
- Utwórz nowy folder o nazwie „Data” w katalogu głównym projektu.
- W folderze „Data” utwórz klasę o nazwie „BlogDbContext”.
Ta klasa będzie reprezentować kontekst bazy danych i będzie wykorzystywana do wykonywania operacji na danych. Klasa BlogDbContext informuje Entity Framework Core, jakie tabele należy utworzyć w bazie danych podczas generowania migracji.
BlogDbContext
using MyBlog.Models;
using Microsoft.EntityFrameworkCore;
namespace MyBlog.Data;
public class BlogDbContext : DbContext
{
public DbSet<Post> Posts { get; set; }
public DbSet<Comment> Comments { get; set; }
public BlogDbContext(DbContextOptions<BlogDbContext> options) : base(options)
{
}
}
- Pola DbSet – BlogPosts i Comments – reprezentują tabele, które mają zostać utworzone w bazie danych.
- Nazwy pól odpowiadają nazwom klas modeli, które definiują strukturę danych dla tabel.
Tworzenie dostawcy zapytań GraphQL
W tym fragmencie kodu tworzymy klasę PostQueryProvider, która służy jako dostawca danych dla interfejsu API GraphQL.
Zatem w folderze „Data” utwórz poniższą klasę:
PostQueryProvider
using MyBlog.Models;
namespace MyBlog.Data;
public class PostQueryProvider
{
[UseProjection]
[UseFiltering]
[UseSorting]
public IQueryable<Post> GetPosts([Service] BlogDbContext context) => context.Posts;
[UseProjection]
[UseFiltering]
[UseSorting]
public IQueryable<Comment> GetComments([Service] BlogDbContext context) => context.Comments;
}
Należy pamiętać, że w powyższej klasie deklarujemy metody GetPosts i GetComments, które zwracają dane z tabel Posts i Comments odpowiednio.
Wykorzystujemy w nich następujące Atrybuty z Hot Chocolate:
- [UseProjection]: Wskazuje, że klienci GraphQL mogą wybrać, które pola danych chcą otrzymać.
- [UseFiltering]: Wskazuje, że klienci GraphQL mogą filtrować dane na podstawie różnych kryteriów.
- [UseSorting]: Wskazuje, że klienci GraphQL mogą sortować dane według różnych pól.
Te atrybuty konfigurują możliwości zapytań udostępniane przez schemat GraphQL dla pola GetPosts i GetComments. Określają, jakie operacje projekcji, filtrowania i porządkowania można zastosować do danych zwracanych przez te pola.
Metody zwracają IQueryable<T>, co umożliwia dynamiczne generowanie zapytań GraphQL. W przypadku Hot Chocolate biblioteka wykorzystuje ten typ do generowania zapytań dynamicznych, dzięki czemu klienci API GraphQL mogą żądać tylko tych danych, których potrzebują.
Konfigurowanie przykładowych danych
Do weryfikacji funkcji GraphQL potrzebne są przykładowe dane. Aby to przyspieszyć, utwórzmy klasę korzystającą z pakietu NuGet Faker.Net do tworzenia danych przy użyciu fragmentów tekstu w stylu Lorem ipsum.
W folderze Data utwórz nową klasę o nazwie „DataSeeder” i umieść w niej poniższy kod:
using MyBlog.Models;
using Faker;
namespace MyBlog.Data;
public static class DataSeeder
{
public static void SeedData(BlogDbContext dbContext)
{
if (!dbContext.Posts.Any())
{
for (int i = 1; i <= 10; i++)
{
var post = new Post
{
Title = Lorem.Sentence(),
Content = Lorem.Paragraphs(3).FirstOrDefault(),
Author = Name.FullName(),
CreatedAt = DateTime.Now,
};
dbContext.Posts.Add(post);
for (int j = 1; j <= 10; j++)
{
var comment = new Comment
{
Content = Lorem.Sentence(),
Author = Name.FullName(),
CreatedAt = DateTime.Now,
Post = post
};
dbContext.Comments.Add(comment);
}
}
dbContext.SaveChanges();
}
}
}
Metoda SeedData otrzymuje parametr typu BlogDbContext, będący kontekstem bazy danych. Sprawdza, czy tabela Posts jest pusta. Jeśli jest pusty, metoda tworzy 10 postów i dla każdego posta 10 losowych komentarzy. Posty są zapełniane losowo generowanymi tytułami, treścią, autorami i datami utworzenia przy użyciu biblioteki Faker.
Komentarze są również wypełnione losową treścią, autorami i datami powstania. Po zapełnieniu bazy metoda zapisuje zmiany przy pomocy dbContext.SaveChanges(). Dzięki temu przy uruchomieniu aplikacji, jeśli nie ma danych, ta metoda utworzy przykładowe dane.
Konfiguracja połączenia z bazą danych
Aby utworzyć połączenie z bazą danych dodamy konfigurację do pliku appsettings.json.
Otwórz plik appsettings.json i dodaj do niego poniższy fragment kodu:
"ConnectionStrings": {
"DefaultConnection": "Data Source=blog.db"
}Konfigurowanie klasy programu
Ostatnim krokiem jest dodanie ustawień bazy danych i GraphQL do klasy Program. Zastąp istniejący kod w pliku Program.cs poniższym kodem:
using MyBlog.Data;
using Microsoft.EntityFrameworkCore;
var builder = WebApplication.CreateBuilder(args);
builder.Services.AddDbContext<BlogDbContext>(options =>
options.UseSqlite(builder.Configuration.GetConnectionString("DefaultConnection")));
builder.Services.AddGraphQLServer()
.AddQueryType<PostQueryProvider>()
.AddProjections()
.AddFiltering()
.AddSorting();
var app = builder.Build();
app.UseHttpsRedirection();
using (var scope = app.Services.CreateScope())
{
var services = scope.ServiceProvider;
var dbContext = services.GetRequiredService<BlogDbContext>();
dbContext?.Database.EnsureCreated();
DataSeeder.SeedData(dbContext);
}
app.MapGraphQL("/graphql");
app.Run();
Sprawdźmy teraz najważniejsze części tego kodu w kontekście wpisu.
Konfiguracja bazy danych:
builder.Services.AddDbContext<BlogDbContext>(options =>
options.UseSqlite(builder.Configuration.GetConnectionString("DefaultConnection")));
Ta część konfiguruje bazę danych przy użyciu SQLite jako dostawcy, w oparciu o parametry połączenia o nazwie „DefaultConnection” podane w pliku konfiguracyjnym.
Konfiguracja GraphQL:
builder.Services.AddGraphQLServer()
.AddQueryType<PostQueryProvider>()
.AddProjections()
.AddFiltering()
.AddSorting();
Ten fragment kodu konfiguruje serwer GraphQL w aplikacji ASP.NET Core. Przyjrzyjmy się bliżej poszczególnym metodom:
Metody konfiguracji
AddGraphQLServer():
Dodaje serwer GraphQL do kontenera DI aplikacji. Ta metoda umożliwia udostępnianie interfejsu API GraphQL przez aplikację.AddQueryType<PostQueryProvider>():
Rejestruje typ zapytania w schemacie GraphQL. KlasaPostQueryProviderdostarcza zapytania dla wpisów na blogu i komentarzy. Oznacza to, że możesz używać API GraphQL do wyszukiwania informacji o wpisach.AddProjections():
Włącza projekcje na serwerze GraphQL. Projekcje umożliwiają klientom GraphQL określenie, jakie pola lub właściwości obiektów mają zostać zwrócone w odpowiedzi na zapytanie. Pozwala to na selektywne pobieranie danych, ograniczając ilość przesyłanych informacji.AddFiltering():
Aktywuje filtrowanie na serwerze GraphQL. Klienci mogą wówczas przesyłać parametry filtrów w zapytaniach GraphQL, aby uzyskiwać dane na podstawie określonych kryteriów, takich jak daty, wartości liczbowe itp.AddSorting():
Włącza sortowanie na serwerze GraphQL. Klienci mogą określić kolejność zwracanych w odpowiedzi na zapytanie wyników.
Podsumowanie
Ten fragment kodu definiuje funkcjonalność interfejsu API GraphQL, określając dostępne typy zapytań, włączając projekcje, filtrowanie i sortowanie. Dzięki temu klienci mogą efektywnie wyszukiwać i manipulować danymi. Pamiętaj, że właściwa konfiguracja serwera GraphQL zapewnia elastyczność i wydajność interfejsu API.
Data seed i tworzenie baz danych
using (var scope = app.Services.CreateScope())
{
var services = scope.ServiceProvider;
var dbContext = services.GetRequiredService<BlogDbContext>();
dbContext?.Database.EnsureCreated();
DataSeeder.SeedData(dbContext);
}
Tutaj Tworzymy zakres usług aplikacji, pobiera kontekst bazy danych i zapewnia, że baza danych zostanie utworzona (jeśli nie istnieje) i wypełniona danymi przy użyciu klasy DataSeeder.
Mapowanie GraphQL:
app.MapGraphQL("/graphql");To mapuje żądania GraphQL na ścieżkę „/graphql”. Zatem po uruchomieniu aplikacji interfejs GraphQL będzie dostępny w punkcie końcowym „/graphql”.
Uruchamianie aplikacji i testowanie API
Kroki do wykonania:
- Uruchom aplikację:
Otwórz terminal i wpisz komendędotnet run. Poczekaj na uruchomienie aplikacji. - Otwórz interfejs GraphQL:
W przeglądarce internetowej wpisz adreshttp://localhost:[PORT]/graphql, gdzie[PORT]jest numerem portu, na którym działa aplikacja. Zazwyczaj ten numer jest wyświetlany w terminalu podczas uruchamiania aplikacji. - Wpisz zapytanie:
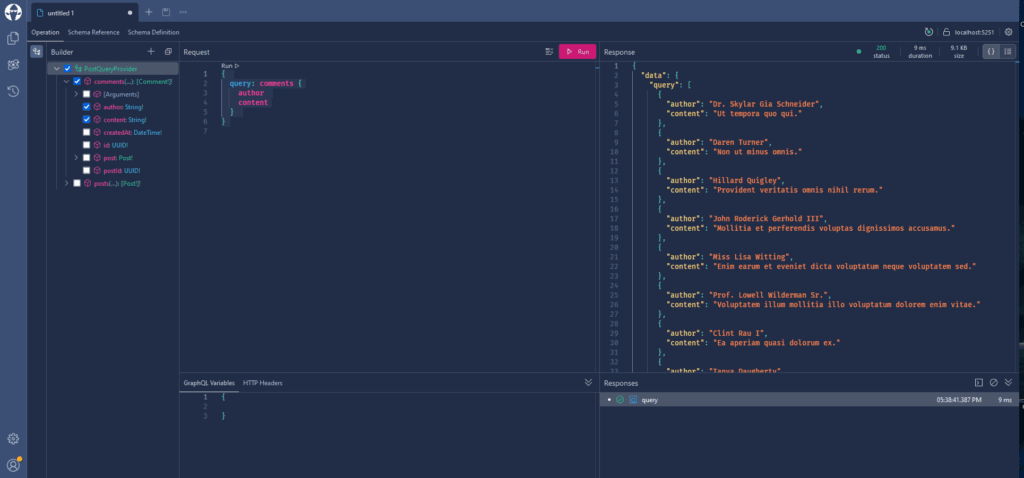
W polu “Request” wklej poniższy kod:
{
query: comments {
author
content
}
}
- Wykonaj zapytanie: Kliknij przycisk “Uruchom”.
- Sprawdź wynik: Wynik zapytania zostanie wyświetlony w prawej zakładce o nazwie “Response“, jak pokazano na obrazku poniżej:
Filtrowanie danych
Możliwe jest filtrowanie danych za pomocą interfejsu GraphQL, co widać na obrazku poniżej. Ponadto istnieją inne opcje filtrowania i sortowania. Możesz sprawdzić wszystkie opcje dostępne w dokumentacji GraphQL. (https://graphql.org/learn/)
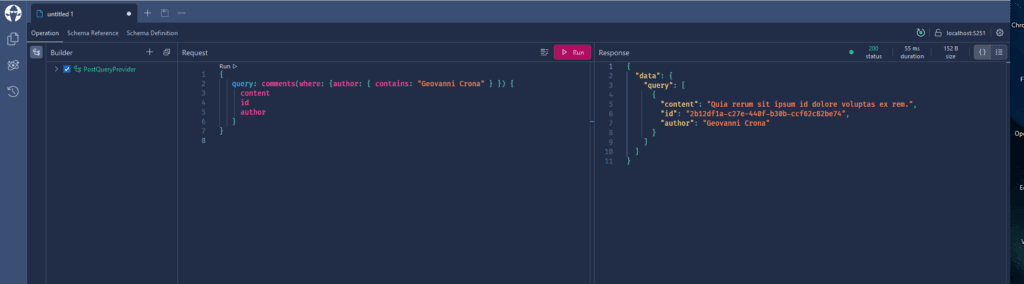
Zwróć uwagę, że w zapytaniu pokazanym na obrazku użyto następującego kodu:
{
query: comments(where: {author: { contains: "Geovanni Crona" } }) {
content
id
author
}
}
który odfiltrował nazwę „Geovanni Crona” i zwrócił dane wprowadzone w zapytaniu, treść, identyfikator i autora.
Wnioski i uwagi końcowe
W tym poście omówiliśmy GraphQL, podkreślając jego zalety i elastyczność w porównaniu z tradycyjnymi interfejsami API REST.
Zbudowaliśmy również projekt ASP.NET Core zintegrowany z GraphQL za pomocą bibliotek Hot Chocolate NuGet. Uruchomiliśmy aplikację i zademonstrowaliśmy pobieranie danych poprzez interfejs GraphQL.
Należy jednak zaznaczyć, że wybór GraphQL nie zawsze jest konieczny. W przypadku prostych aplikacji z niewielkim wolumenem danych i relacji między nimi REST API może okazać się wystarczająco dobrym rozwiązaniem.
GraphQL nie stanowi konkurencji dla REST API, lecz jest kolejną opcją w arsenale narzędzi do tworzenia aplikacji internetowych na dużą skalę.
Zalety GraphQL:
- Elastyczność: Klienci mogą pobrać tylko potrzebne dane, co zwiększa wydajność.
- Typizacja: Silna typizacja zapewnia bezpieczeństwo i łatwiejsze debugowanie.
- Schemat: Jasno określony schemat ułatwia zrozumienie struktury danych.
Wady GraphQL:
- Złożoność: Krzywa uczenia się jest wyższa w porównaniu z REST API.
- Obsługa: Dostępność narzędzi i bibliotek jest mniejsza niż w przypadku REST API.
Podsumowanie:
GraphQL oferuje szereg zalet dla aplikacji z dużą ilością danych i złożonymi relacjami. Należy jednak wziąć pod uwagę również jego wady i rozważyć, czy REST API nie będzie lepszym wyborem dla prostszych projektów.
Pamiętaj, że wybór odpowiedniego interfejsu API zależy od specyfiki projektu i jego wymagań.
Zawsze szukałem lepszego sposobu na pobieranie danych z moich API i myślę, że GraphQL może być rozwiązaniem, którego szukałem. Szczególnie podoba mi się pomysł precyzyjnego określania, jakich danych potrzebuję, zamiast otrzymywać wszystko i musieć je filtrować po stronie klienta. To oszczędzi mi czas i transfer danych, co jest szczególnie ważne w przypadku moich aplikacji mobilnych.
Autor wykonał świetną robotę, wyjaśniając złożone zagadnienia w prosty sposób. Nawet jako początkujący programista z łatwością mogłem zrozumieć koncepcje GraphQL. Przykład z zamawianiem pizzy był szczególnie trafny!
GraphQL to prawdziwa rewolucja w sposobie interakcji z API. Dzięki tej technologii możemy pożegnać się z marnowaniem czasu i danych na pobieranie informacji, których nie potrzebujemy. To ogromna korzyść dla zarówno programistów, jak i użytkowników.
Zdecydowanie polecam ten artykuł każdemu, kto chce dowiedzieć się więcej o GraphQL. Jest to świetne źródło wiedzy dla zarówno początkujących, jak i doświadczonych programistów.